London can sink, we're fine
“redundancy” 37 matches last month
ITFrame is a vital component of our our infrastructure, it is designed to be the central hub and database of Cast, Control, Apps, Player and DJ. Unfortunately last month(s) was/were not great. Despite the redundancy we had built we had one issue we could not solve. The infrastructure. ITFrame was hosted at OVH Public Cloud, which had several issues to even complete downtime since we switched to it from RunAbove (which has been closed in favor for OVH). This we wanted to solve.
OVH Cloud is something we wanted to avoid in an improved setup, we had too much trouble and no understanding of these. On the path for a new provider we met Linode (where Status was hosted shortly after as a test). Linode has the perfect offer for the infrastructure we wanted to build. Only the OVH incidents made us careful.
Redundancy
Redundancy, redundancy, redundancy. How can we keep ITFrame up if the UK (London is the location of one of the DCs) sinks? Simple place a 2nd copy somewhere else, Germany. We set up ITFrame to serve in 2 locations in the world and share the database so it doesn’t matter if you go to London or Frankfurt. This allows us to stay up in the worst case scenarios such as broken fibre cables or any other major issue.
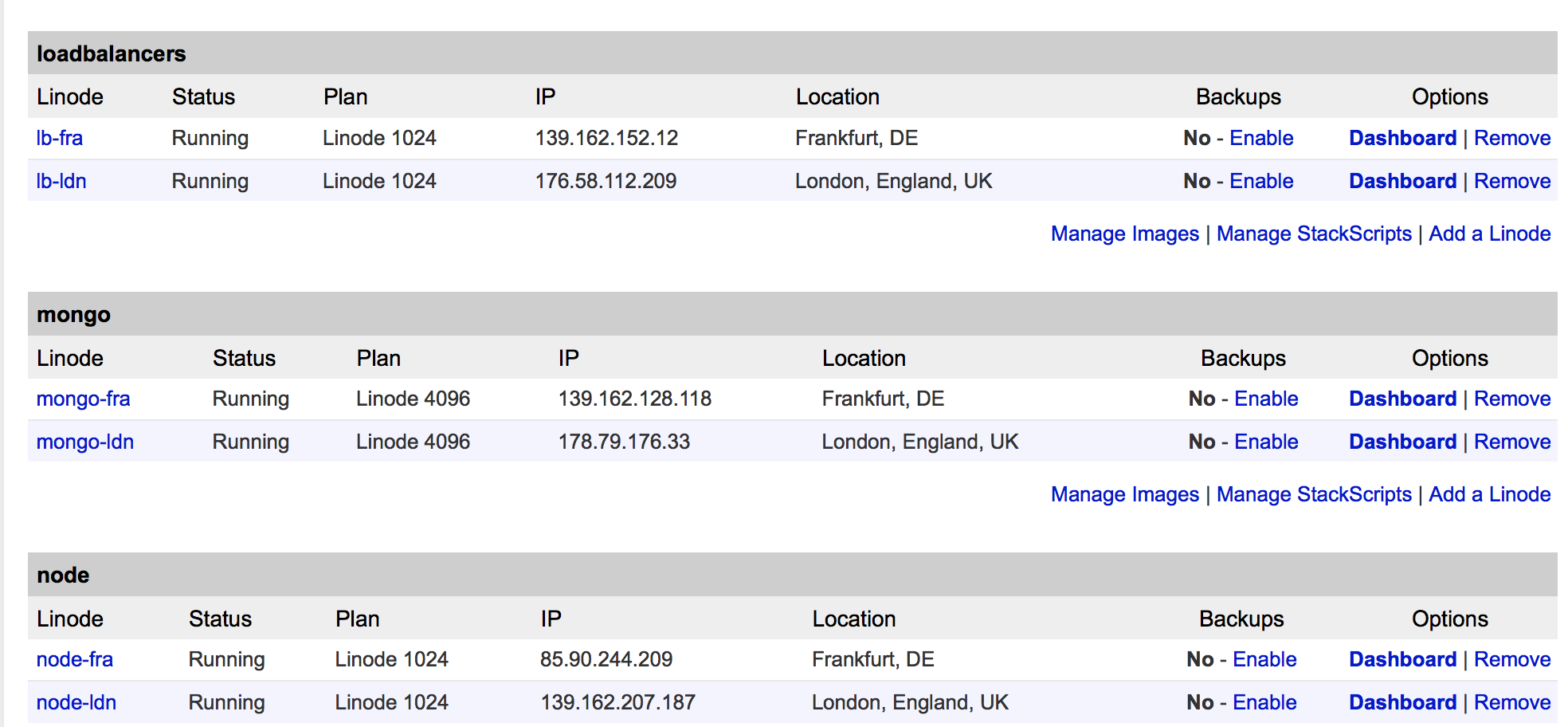
ITFrame’s setup exists of 3 parts. A loadbalancer, a server to run the Node.js and a MongoDB database.
The first 2 are simple, just set them up as normal with the only difference of adding a backup rule in Nginx to route to the other datacenter in case it’s local node is down. By adding both IPs in the DNS the local user is balanced between those 2 locations.
MongoDB on the other side is another story. We tested the network and there is only 10ms of ping between London and Frankfurt. So database traffic between the two couldn’t be an issue. As MongoDB has a mechanism called replica sets we used that setup. This means one server is the write master and others clone the database by following the oplog. In case you need to balance load too you can ask the driver to chose the nearest to read and the master only to write to. In case you want to do this with 2 or an other even count of servers you need one more or an arbiter, that is a server that only takes part in the votes. One of the loadbalancers is a perfect candidate for that.
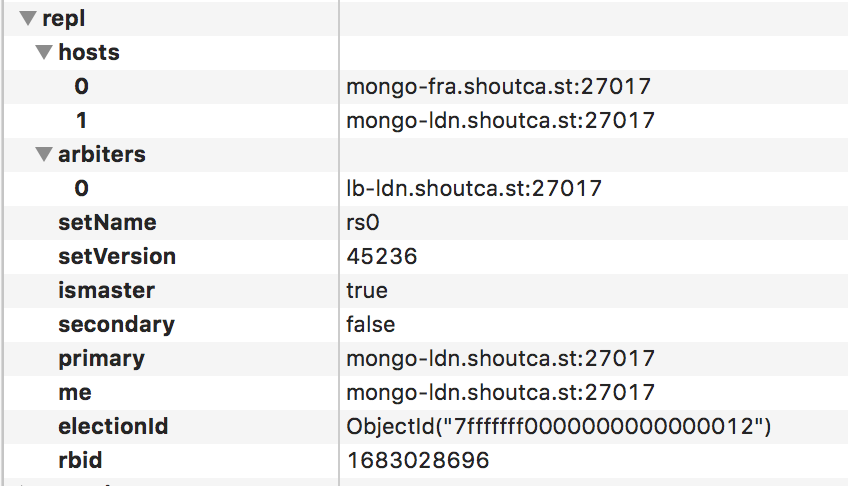 A side note here is that the cluster started with the
A side note here is that the cluster started with the mongo-fra as the primary meaning that one went down for a small period, also a proof that it works as nobody noticed.
So how secure is sending data under Germany vie The Netherland under the channel over to London past a well known NSA POP. Very.
 By using Let’s encrypt we send all traffic over strong TLS and auto-renew it every few months. This way all info send from to and between the database servers is secure meaning no sensitive or insensitive data can ever be captured (never say never, but they will have to do their best).
By using Let’s encrypt we send all traffic over strong TLS and auto-renew it every few months. This way all info send from to and between the database servers is secure meaning no sensitive or insensitive data can ever be captured (never say never, but they will have to do their best).
Expanding
Currently only ITFrame has this as it will become more and more important. While designing the software we already made it so it can scale well and be set up redundant. The question is will we expand this to Cast? Probably, the infrastructure for Cast is highly decentralized a hardware server is nothing but a dumb thing that executes code, there is not a single bit stored on the disks. That allows us to later on set up a system that can move your Cast server to another datacenter in case something happens. The only issue is that we host Cast on special hardware which is currently only available on one location.
The result
At time of publishing we can report that over the past 3 months we had 0 incidents of downtime where from 0 had been due external issues. (source: https://status.shoutca.st)