The ITFrame Swarm
So a year ago I wrote London can sink, we’re fine on how we made sure ITFrame would stay up all the time (*as much as possible). This setup proved itself over the year by having exelent uptime and mitigating disasters when one of the 2 datacenters had an issue. Scaling. For now all those nodes had been set up by hand (and disk images). This didn’t scale well.
When the time came to update Node.js I stood still and asked myself, why this Fish loop to update all servers… This made me containerize ITFrame, make it deploy it via Travis-CI and there we go. Now how will we manage those containers? We could just do it manual but why did we do all the hard work (2 minutes) for containerizing ITFrame?
What are our options: Kubernetes, Docker Swarm or maybe Dispatch? Dispatch would be a logical choise as it us developed by us, unfortunally it isn’t production ready yet. Kubernetes is maybe overkill and also a hard setup if you’re not on GKE or Amazon. Docker Swarm?
It all started in a train ride to school. Googling arround on how to setup and secure Docker Swarm (spoiler: out of the box). Checking off all the requirements in my head. First of all it had to suppor Docker, duuuh. I needed to have an encrypted internal network, check! I also needed to be able to devide the clusters per geographical zone and per use (worker or load balancer), uuh… unclear. So I went to look further. --constraint was there? Turns our that can be linked to --label so that would work. What to people say on load balancing? HAProxy, okay, not in a container??? If you go containers, go all the way! So if I want to container our loadbalancers I need service discovery, check!
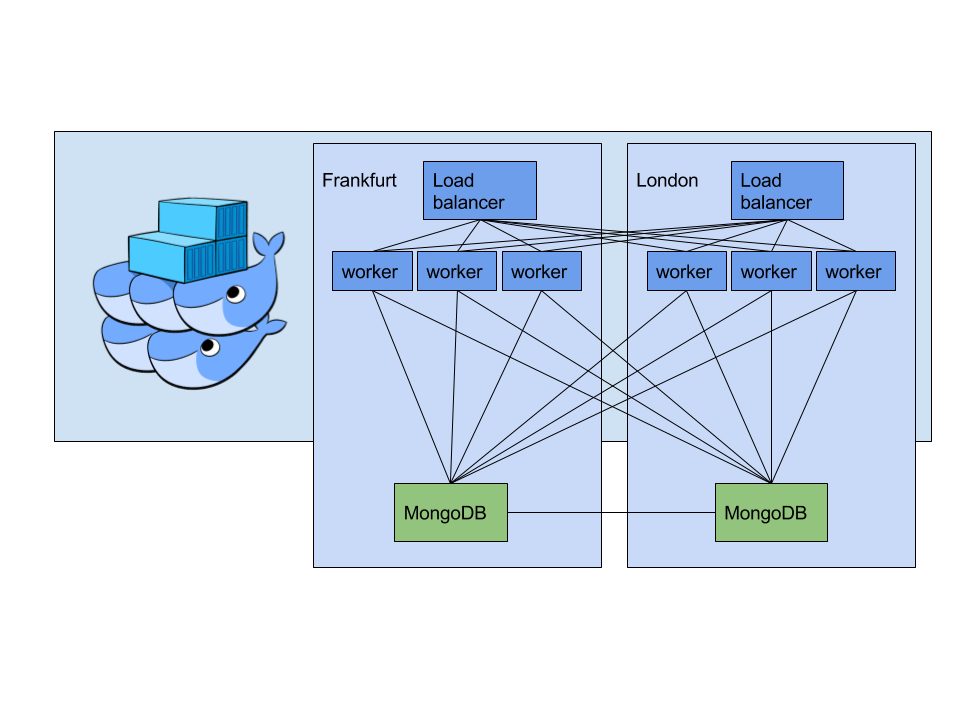
Now I know what I want it is setup time! Easy right? Well I am suprised it took me less than a day with all those issues. So I started out with setting up 2 Linodes to use as load balancers. Wrote a StackScript for easy deploy of Docker on top of Debian.
docker swarm init was easy, chosing IPv6 for the advertising IP to be ready for the future. Setting up a network and link a container to it. Error… How? failed: subnet sandbox join failed for "10.255.0.0/16": error creating vxlan interface: operation not supported". Turns out the Linode kernel doensn’t support vxlan. Good you can set it to just boot to GRUB. Deleting the Linodes to reinstall with the Debian kernel and starting over.
Next up deploying a service was as easy as docker service create. Okay now let’s set up 2 alpine containers and a network between them. Simple! Now let’s try pinging… Host not resolved? Oops… How can that happen? On the same machine that worked. Failed to join memberlist [2a01:7e01::f03c:91ff:fe60:5b29] on retry: 1 error(s) occurred:\n\n* Failed to resolve 2a01:7e01::f03c:91ff:fe60:5b29: too many colons in address 2a01:7e01::f03c:91ff:fe60:5b29 Turns out Docker networking uses Hashicorp’s memberlist module which for some reason had this bug fixed. So I gave them some extra unit tests and reported the issue to Moby. So far for IPv6 everywhere.
Going back to IPv4 for cluster comminucation.
ITFrame worker nodes: check. Loadbalancer in Frankfurt: check. Loadbalancer in London: oops… So by default --publish mesh routes all traffic back to one server. Not what we want here. After tons of Googling (on DuckDuckGo of course) I stumbled opon a mysterious mode=host thing. It turns our that the publish syntax can be extended --publish mode=host,target=80,published=80 disables the routing! Only the place I found it was a bug report to tell it was broken. It forgot to check if the mode wasn’t host to throw the error that the port was in use. Good that the issue was just fixed on the master, so going to the dev build it was! Once it was added to publish in mode host I got yet another error… Networks were broken in the dev build, so back to stable it was. Since the check is only on the create it just worked!
200 browser tabs and at least as much SSH sessions open it works!